
前回に引き続き、Pandasの説明をしていきます。
今回は同じ種類のものをグループ化して、データをより整理していきます。
目次
グループ作成前のデータ
>>>【Pandas入門】データをソートして、昇降順を並び替える方法|Anacondaでデータ分析
前回の記事で、ageのデータをソートして、見やすくしました。
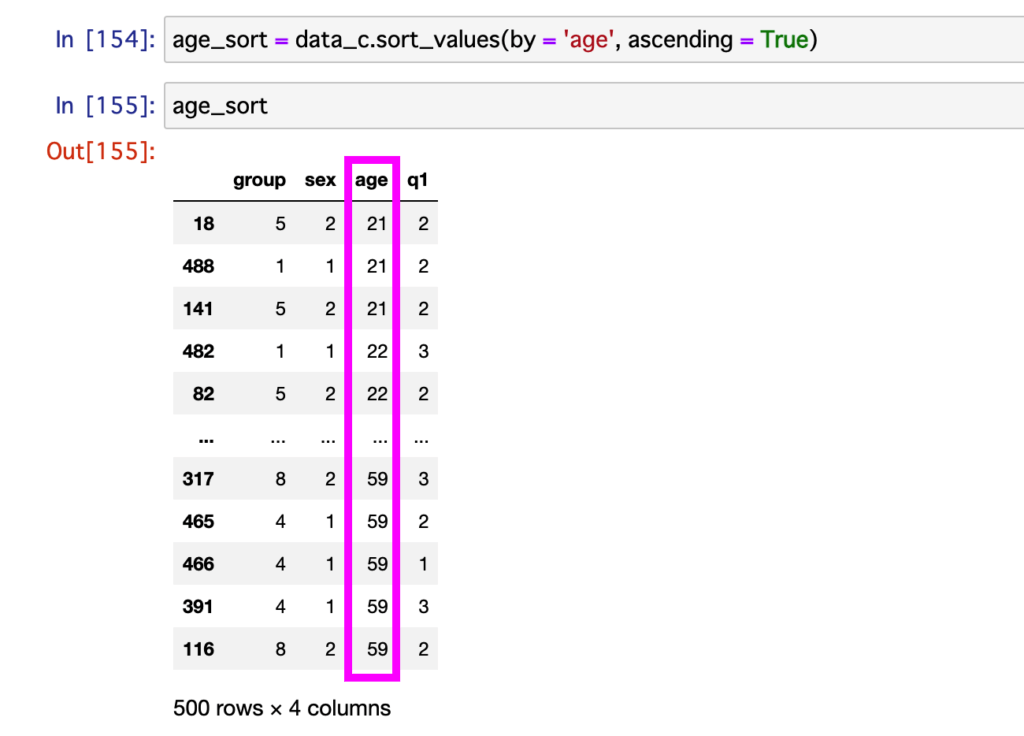
今回は、さらに年齢別にq1のスコアの平均値を出していこうと思います。
そこで必要になるのが、groupbyメソッドです。
groupbyによってデータをまとめる
さっそく、age を年齢別の束にしていきます。
age_group = age_sort.groupby('age').q1.mean()結果、以下の表をつくることができました。
グループを作成するだけでなく、meanメソッドによって、年齢ごとのq1スコアの平均値を出しています。
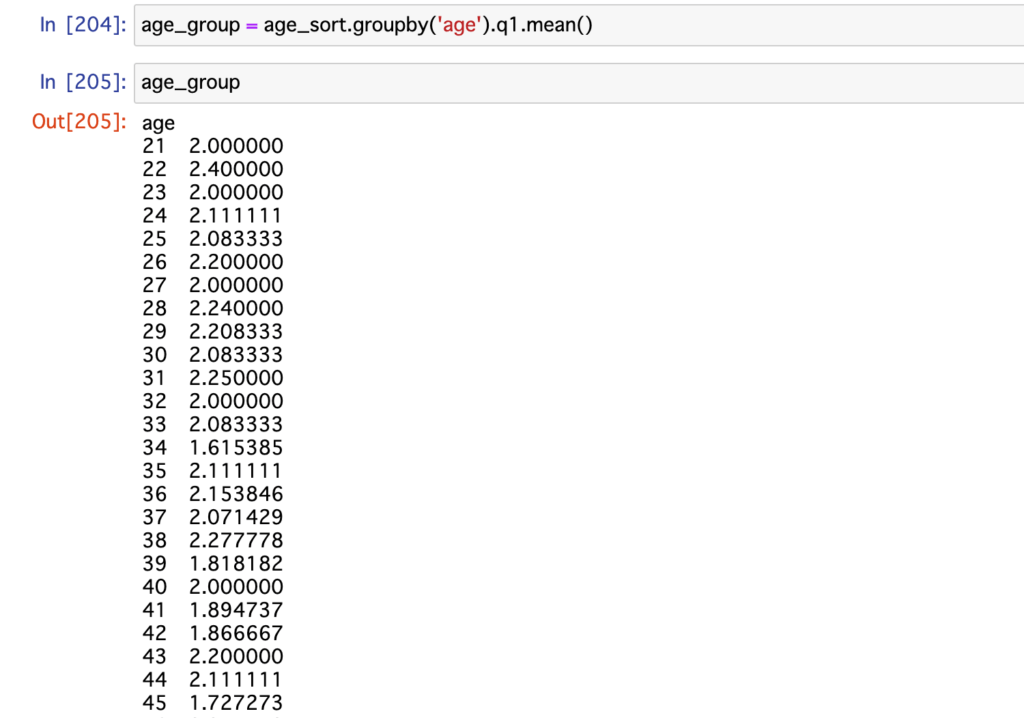
※画像の表は途中で切れています。
でも、これだけだと何がなんだか分からないね
じゃあ、このデータをもとにグラフを作成してみよう!
フレームワークを作成してデータの可視化
まず、先ほど作成したage_groupは、Seriesという形式になっているので、
これをDateFrameの形式に置き換えます。
(可視化するためには、DataFrameに置き換える必要があります。)
df = pd.DataFrame(age_group)df2 = df.rename(columns = {'q1' : 'q1_mean'})より分かりやすくするために、q1というカラム名を、q1_meanという名前に変更しました。
実際にできあがったデータフレームが以下です。
df2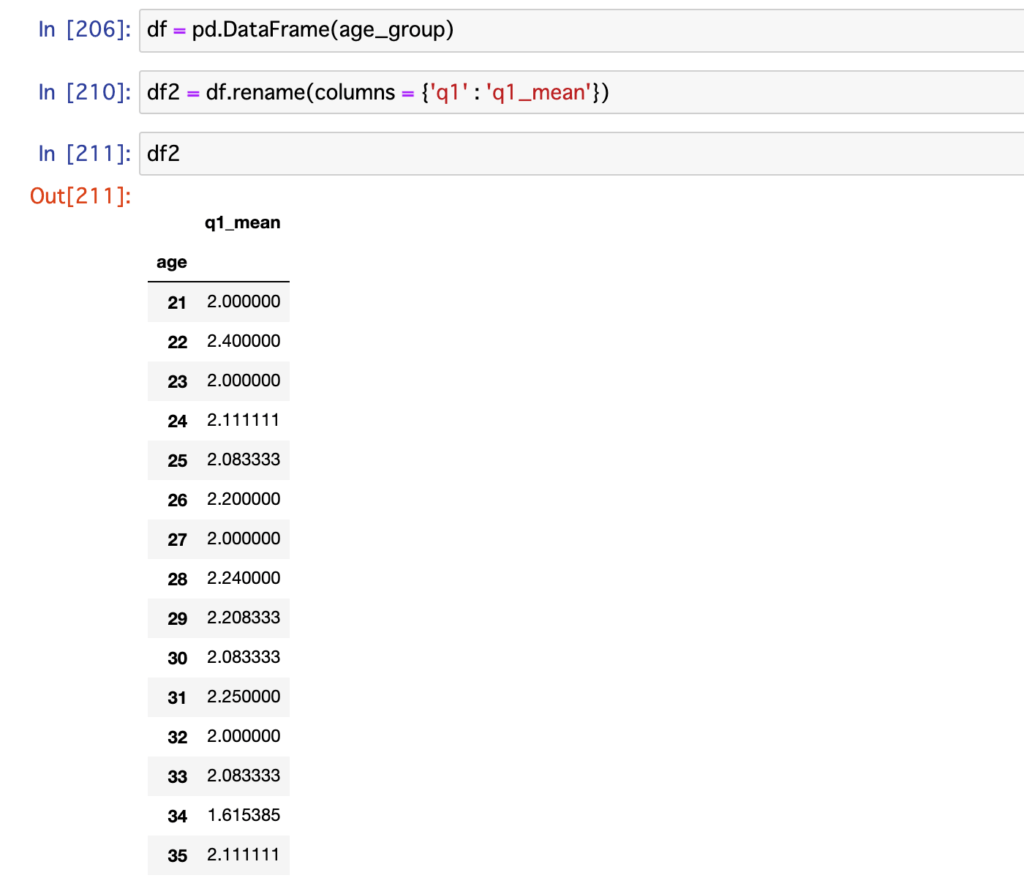
※画像の表は途中で切れています。
さっきよりも、しっかりした表になりました。
データの可視化
出来上がった表を可視化できるようにグラフを作成してみます。
df2.plot(title='q1 score')コードを実行すると、こんなグラフができました。
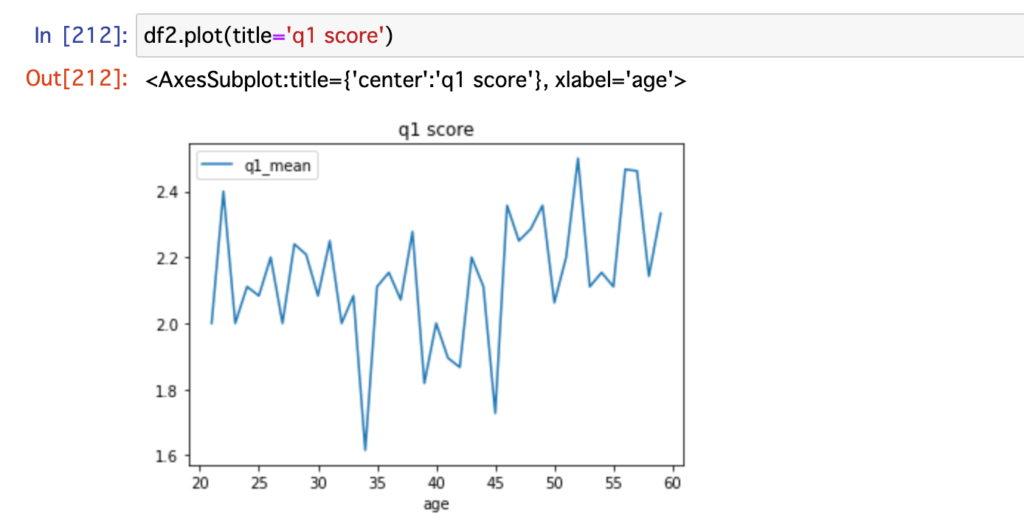
これなら、さっきよりも年齢とq1の平均値との関係性が分かるようになったね!
うん、グラフも簡単に作成できたね!
まとめ
データをgroupbyを使うことで整理できたので、
可視化してよりデータの変化を捉えることができました。
どんどんgropbyを使って、使い方をマスターしていきましょう。


![Anaconda Proceed ([y]/n)? の対処法の巻](https://clione33.online/wp-content/uploads/2022/04/anaconda-proceed-y-or-n.png-300x158.webp)





コメント